1. DreamFusion 소개
DreamFusion 은 2D 이미지 생성 모델인 Diffusion Model 과 3D reconstruction model인 NeRF 을 통합한 새로운 모델로서, 사전학습된 2D text to image 모델을 사용해서 text(condition) 입력에 부합하는 3D 모형을 생성해내는 것이 목표다. 3D data 학습 없이 3D data를 생성해내는 zero shot 모델로서 2D model을 활용하여 여러 가능성을 보여준 모델이다.
어떻게 학습하는지를 간단하게 살펴보면,
텍스트 입력을 기반으로 디퓨전 모델이 생성한 가상의 2D 이미지를 바탕으로 NeRF 가 3D 모형을 만들고 다시 2D 로 렌더링했을 때, 이 이미지와 처음 디퓨전 모델이 생성한 2D 이미지와 얼마나 일치하는지를 비교하며 학습하는 것이다.
전체적인 흐름은 다음과 같다.
1. NeRF (3d reconstruction 로서 Instant-NGP도 가능) 를 통해 3D 장면을 생성 : 먼저 텍스트를 디퓨전 모델을 넣어서 해당 텍스트를 반영한 가상의 2D 이미지를 생성한다. 그리고 이 2D 이미지를 기반으로 3D 장면을 만들어낸다. (처음에는 당연히 텍스트 조건에 맞지 않을 수 있음, 그리고 여기서 생성한 가상의 2D 이미지가 '이상적인 2D 이미지')
2. 렌더링과 노이즈 추가 : 3D 장면을 2D 이미지로 렌더링 하고, 이 이미지에 noise 를 추가한다.
3. Diffusion model에 입력 : Diffusion model 에 noise를 추가한 이미지와 원하는 text를 넣어서 condition 에 맞게끔 이미지를 생성한다. (diffusion model의 denoising 과정을 활용)
4. Loss 계산 및 역전파 수행 : (1.에서 텍스트를 기반으로 디퓨전 모델이 처음 생성한 원본 2D 이미지)와 (3D 장면을 2D 로 렌더링 하고 노이즈를 추가한 후 디퓨전 모델을 통해 만들어진 이미지)를 비교하여 Loss 를 계산하 역전파를 통해 NeRF의 파라미터를 업데이트 한다. 즉, NeRF가 현재 text 에 잘 맞는 형태로 학습 될때까지 최적화 과정을 반복한다.
2. SDS (Score Distillation Sampling)
SDS는 사전학습된 디퓨전 모델(여기서 UNet)의 지식을 다른 도메인(여기서 3D)로 전달하는 방법이다. 여기서 Score는 디퓨전 모델의 노이즈 예측을 의미한다.
SDS는 noise 의 차이를 계산하면서 업데이트를 하게 된다. 좀 더 쉽게 설명하자면, 노이즈가 추가된 이미지를 Diffusion model 의 UNet에 넣어 어떤 노이즈가 추가되었는지를 예측한다. 그렇다면 이 예측된 노이즈는 현재 이미지에서 제거해야할 노이즈 패턴인 것이다. 이 예측된 노이즈와 실제로 추가된 노이즈 간의 차이를 기반으로 손실을 계산한다. 그래서 아래 식에서 eps_hat과 eps의 차이를 포함하고 있다.
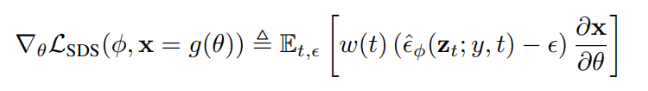
SDS 손실은 노이즈 예측의 그래디언트를 활용하여 계산된다.
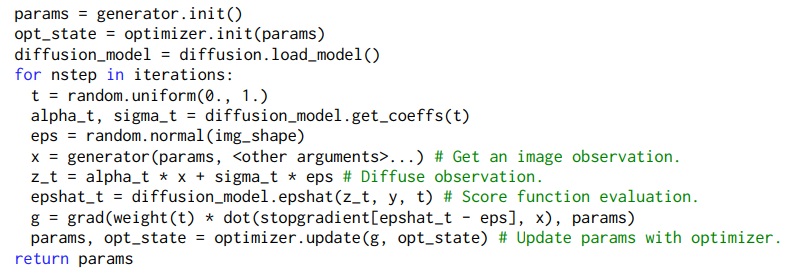
- z_t가 랜덤 노이즈를 더해 새로운 이미지를 만든 것이다.
- epshat_t 가 노이즈가 더해진 이미지와 caption(y) 와 t step 으로 예측된 노이즈를 의미한다.
- g 가 예측된 노이즈 (epshat_t)와 실제 노이즈 (eps) 간의 차이를 이용하여 계산된 그래디언트다 (위의 식과 동일)
3. 헷갈렸던 점
Q1. Loss 를 구할 때 diffusion model 을 통해 만든 이미지와 어떤걸 비교해서 loss를 구하는지 궁금했다. 예를 들어, linear regression 의 경우 선형 모델을 통해 얻은 예측값과 실제값의 차이를 통해 그래디언트를 계산하는데, 이 경우 어떤 것이 ground truth 인지 궁금했다.
A1. gpt 에 의하면,
1) 텍스트-이미지 정합성
모델이 생성한 이미지가 텍스트 조건과 얼마나 잘 맞는지 평가한다. 텍스트 설명과 생성된 이미지를 비교하여 일치도를 평가한다.
2) 2D 이미지와 3D 모델 간의 일치성
3D 장면에서 렌더링된 2D 이미지와 실제 목표 이미지 간의 차이를 비교한다.
Q2. 처음에 여러 2d 이미지를 받아 NeRF를 통해서 3d 물체로 바꾸고, 다시 rendering 을 통해 3d 를 2d 로 바꾸어서 noise 를 추가하는데 이럴거면 애초에 input으로 받은 2d 이미지를 사용하면 안되는건지 궁금했다. 단지, 여러 2d 이미지를 하나의 3d 객체로 만들고 하나의 2d image 로 바꾸기 위함인지 궁금했다.
A2. gpt 에 의하면,
1) 3D 구조의 중요성
텍스트 기반의 3D 장면을 생성하면, 2D 이미지로는 표현할 수 없는 깊이와 공간 정보를 포착할 수 있다. 또한, 다양한 시점에서의 세부 정보를 제공할 수 잇어, 텍스트 설명을 더 잘 반영할 수 있다.
2) 디퓨전 모델의 이점
2D -> 3D -> 2D의 사이클 : 3D 장면을 통해 이미지를 생성하면 시각적 표현과 구조를 반영하여 복잡한 장면과 객체의 구조를 학습할 수 있다.
'AI Tech 7기 > Computer Vision' 카테고리의 다른 글
| AE(Auto Encoder), VAE(Variational Auto Encoder) (1) | 2024.09.04 |
|---|---|
| CNN 시각화 (0) | 2024.08.29 |
| Vision Transformer (0) | 2024.08.29 |
| CNN 아키텍쳐 (0) | 2024.08.29 |