
Transformer 모델에 영감을 받아 vision 분야에도 도입하게 된 Vision Transformer 이다. 이후, ViT 를 backbone으로 한 다양한 vision architecture들이 제안되고 있다.
Transformer 모델의 디코더는 사용하지 않고 인코더만 사용하기 때문에 input 파트 부분이 중요하다.
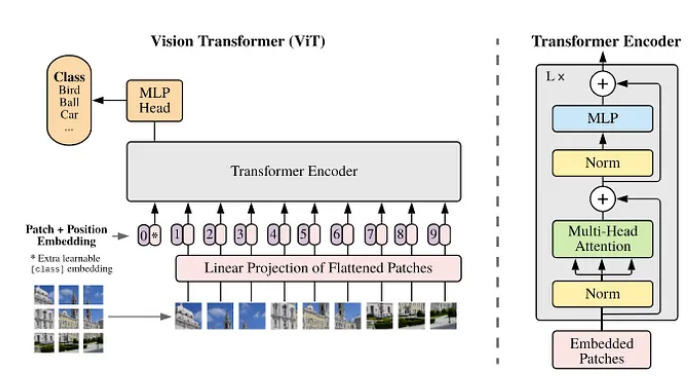
구조는 위와 같고, 크게 4가지 단계로 나눌 수 있다.
1. 이미지를 작은 패치로 나누어 토큰화 하
2. Position Embedding 더하기
3. Transformer Encoder
4. MLP (Classification) Head
(가정)
img_size = (224, 224), patch_size = (16, 16), stride = 16
1. 이미지를 작은 패치로 나누어 토큰화 하기
- 16x16 kernal size, (16, 16) stride를 가지는 2D convolutional filter를 이용하여 224x224의 이미지를 14x14의 패치로 나누는 단계

Conv2d filter 가 하는 일은 2가지다.
1) 원래 (224, 224) 이미지 사이즈를 14*14 개의 (16, 16) 의 작은 패치로 나눈다.
2) 각 패치를 768(16*16*3) 크기의 벡터로 변환
-> 14*14 개의 패치가 생성되므로 출력 형태는 14*14 개의 768 크기의 벡터가 된다.
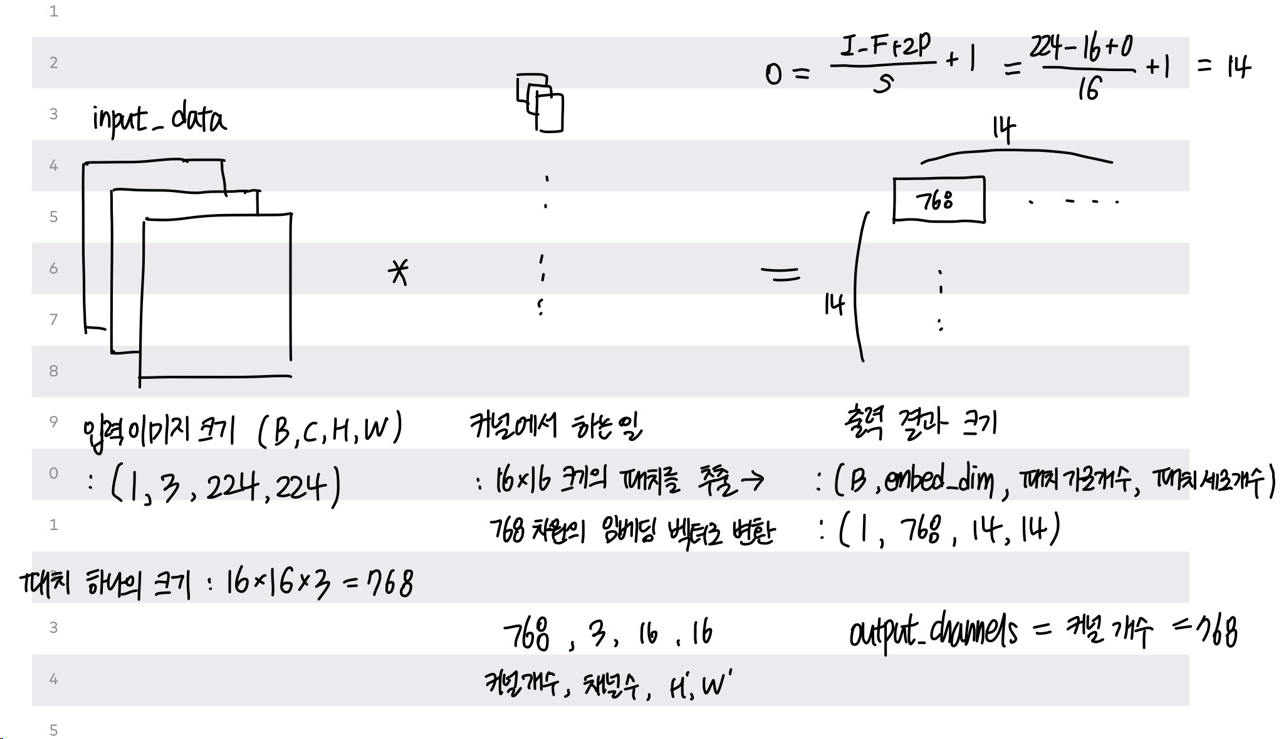
self.proj = nn.Conv2d(in_channels=3, out_channels=768, kernel_size=16, stride=16)
# (1, 3, 224, 224) -> (1, 768, 14, 14)
그렇다면 이제 모델의 입력 형태로 맞추어 주면 된다. 기본적으로 sequence 데이터를 입력으로 받기 때문에 flatten, transpose 과정이 필요하다.
x = self.proj(x).flatten(2).transpose(1,2)
# (1, 3, 224, 224) -> (1, 768, 14, 14) -> (1, 768, 196) -> (1, 196, 784)
* patch vs grid
patch : 원본 이미지에서 잘라진 작은 이미지 하나하나 ( 크기 : 16*16, 개수 : 14*14 )
grid : 이미지가 패치들로 나누어져 배열된 형태로, 패치들의 2D 배열의 가로와 세로 크기를 의미 (14*14)
즉, 224*224 크기 이미지를 16*16 패치로 나누면 총 196개의 패치 생성
(H, W) : shape of original image
C : the number of channels
(P, P) : shape of each image patch
N = H*W/P*P : the number of patches
2. Position Embedding 더하기
- 학습가능한 position embedding 벡터를 patch embedding 벡터에 더하고 transformer encoder에 넣는 단계

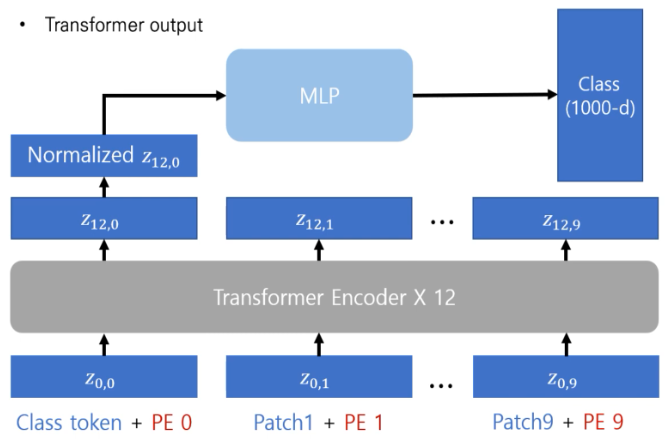
CLS 토큰이 patch embedding vector 맨 앞에 concat 되고, position embedding을 더하는 과정이다.
< CLS 토큰이란? >
사진 속 *에 해당하는 부분이 CLS 토큰인데, 모든 이미지(문장)의 가장 첫 번째 토큰으로 삽입되며, 입력 이미지 전체에 대한 정보를 요약해서 최종적으로 클래스 레이블을 예측할 수 있도록 돕는다. 마지막 layer 로 넘겨줄 때 이 CLS 토큰을 넘겨서 Classification 을 하게 된다.
그렇다면 CLS 토큰 shape 은 (1, 1, 784) 형태가 되겠다.
transformer_input = torch.cat((model.cls_token, patches), dim=1) + pos_embed
# (1, 196, 784) + (1, 1, 784) = (1, 197, 784)
< Position Embedding 이란? >
Transformer 모델은 flatten 등의 과정을 거치게 되어 위치 정보가 사라졌기 때문에 이를 통해 위치 정보를 제공해야한다.
사진 속 보라색 부분으로 숫자가 써있는 부분이다. 기존에 위에서 만든 (분홍) 에 이를 더해주는 것이다.
그렇기에, shape은 위와 같이 (1, 197, 784) 형태이다.
3. Transformer Encoder
- embedded 된 patch 들을 encoder 에 넣는 단계
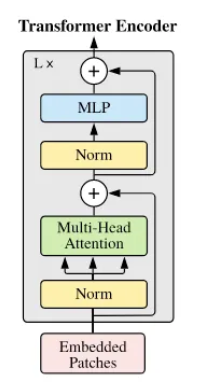
임베딩 차원 : 768, head 수 : 12(지정), head 차원 : 768/12 = 64
1) Layer Norm 을 통해 배치마다 시행한다.
2) Multi-Head Attention
원본 입력 텐서 (197, 768) 을 fc layer (linear layer) 을 통과해서 (197, 2304) 로 만든다. (dimension expansion)
이를 다시 (197, 3, 12, 64) 로 만들어서 각각 Q, K, V 벡터를 만든다.
q = qkv[:, 0].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
k = qkv[:, 1].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
v = qkv[:, 2].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
3) Attention score 계산
attention_matrix = torch.matmul(F.softmax(torch.matmul(q, kT) / q.shape[-1]**(1/2), dim=-1), v)
dim이 -1인 이유는 각 row 내에서 softmax 취해서 attention score을 구해야 하기 때문이다.
인코더부터의 전체적인 흐름은, fc layer를 통해서 dimension 확장하고, Q, K, V 나눠서 attention score 계산 후, 헤드의 출력을 결합하고 MLP 거쳐서 해당 class label을 출력하는 것이다.
4. MLP (Classification) Head
- Transformer encoder의 output의 첫번째가 MLP head에 입력으로 들어가 final classfication 결과를 얻습니다

output vector의 0번째 값은 class token input에 대응되므로, flatten한 후 MLP Head 를 거쳐 class label을 얻는다.
'AI Tech 7기 > Computer Vision' 카테고리의 다른 글
| DreamFusion (1) | 2024.09.06 |
|---|---|
| AE(Auto Encoder), VAE(Variational Auto Encoder) (1) | 2024.09.04 |
| CNN 시각화 (0) | 2024.08.29 |
| CNN 아키텍쳐 (0) | 2024.08.29 |
Transformer 모델에 영감을 받아 vision 분야에도 도입하게 된 Vision Transformer 이다. 이후, ViT 를 backbone으로 한 다양한 vision architecture들이 제안되고 있다.
Transformer 모델의 디코더는 사용하지 않고 인코더만 사용하기 때문에 input 파트 부분이 중요하다.
구조는 위와 같고, 크게 4가지 단계로 나눌 수 있다.
1. 이미지를 작은 패치로 나누어 토큰화 하
2. Position Embedding 더하기
3. Transformer Encoder
4. MLP (Classification) Head
(가정)
img_size = (224, 224), patch_size = (16, 16), stride = 16
1. 이미지를 작은 패치로 나누어 토큰화 하기
- 16x16 kernal size, (16, 16) stride를 가지는 2D convolutional filter를 이용하여 224x224의 이미지를 14x14의 패치로 나누는 단계
Conv2d filter 가 하는 일은 2가지다.
1) 원래 (224, 224) 이미지 사이즈를 14*14 개의 (16, 16) 의 작은 패치로 나눈다.
2) 각 패치를 768(16*16*3) 크기의 벡터로 변환
-> 14*14 개의 패치가 생성되므로 출력 형태는 14*14 개의 768 크기의 벡터가 된다.
self.proj = nn.Conv2d(in_channels=3, out_channels=768, kernel_size=16, stride=16)
# (1, 3, 224, 224) -> (1, 768, 14, 14)
그렇다면 이제 모델의 입력 형태로 맞추어 주면 된다. 기본적으로 sequence 데이터를 입력으로 받기 때문에 flatten, transpose 과정이 필요하다.
x = self.proj(x).flatten(2).transpose(1,2)
# (1, 3, 224, 224) -> (1, 768, 14, 14) -> (1, 768, 196) -> (1, 196, 784)
* patch vs grid
patch : 원본 이미지에서 잘라진 작은 이미지 하나하나 ( 크기 : 16*16, 개수 : 14*14 )
grid : 이미지가 패치들로 나누어져 배열된 형태로, 패치들의 2D 배열의 가로와 세로 크기를 의미 (14*14)
즉, 224*224 크기 이미지를 16*16 패치로 나누면 총 196개의 패치 생성
(H, W) : shape of original image
C : the number of channels
(P, P) : shape of each image patch
N = H*W/P*P : the number of patches
2. Position Embedding 더하기
- 학습가능한 position embedding 벡터를 patch embedding 벡터에 더하고 transformer encoder에 넣는 단계
CLS 토큰이 patch embedding vector 맨 앞에 concat 되고, position embedding을 더하는 과정이다.
< CLS 토큰이란? >
사진 속 *에 해당하는 부분이 CLS 토큰인데, 모든 이미지(문장)의 가장 첫 번째 토큰으로 삽입되며, 입력 이미지 전체에 대한 정보를 요약해서 최종적으로 클래스 레이블을 예측할 수 있도록 돕는다. 마지막 layer 로 넘겨줄 때 이 CLS 토큰을 넘겨서 Classification 을 하게 된다.
그렇다면 CLS 토큰 shape 은 (1, 1, 784) 형태가 되겠다.
transformer_input = torch.cat((model.cls_token, patches), dim=1) + pos_embed
# (1, 196, 784) + (1, 1, 784) = (1, 197, 784)
< Position Embedding 이란? >
Transformer 모델은 flatten 등의 과정을 거치게 되어 위치 정보가 사라졌기 때문에 이를 통해 위치 정보를 제공해야한다.
사진 속 보라색 부분으로 숫자가 써있는 부분이다. 기존에 위에서 만든 (분홍) 에 이를 더해주는 것이다.
그렇기에, shape은 위와 같이 (1, 197, 784) 형태이다.
3. Transformer Encoder
- embedded 된 patch 들을 encoder 에 넣는 단계
임베딩 차원 : 768, head 수 : 12(지정), head 차원 : 768/12 = 64
1) Layer Norm 을 통해 배치마다 시행한다.
2) Multi-Head Attention
원본 입력 텐서 (197, 768) 을 fc layer (linear layer) 을 통과해서 (197, 2304) 로 만든다. (dimension expansion)
이를 다시 (197, 3, 12, 64) 로 만들어서 각각 Q, K, V 벡터를 만든다.
q = qkv[:, 0].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
k = qkv[:, 1].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
v = qkv[:, 2].permute(1, 0, 2) # (197, 12, 64) -> (12, 197, 64)
3) Attention score 계산
attention_matrix = torch.matmul(F.softmax(torch.matmul(q, kT) / q.shape[-1]**(1/2), dim=-1), v)
dim이 -1인 이유는 각 row 내에서 softmax 취해서 attention score을 구해야 하기 때문이다.
인코더부터의 전체적인 흐름은, fc layer를 통해서 dimension 확장하고, Q, K, V 나눠서 attention score 계산 후, 헤드의 출력을 결합하고 MLP 거쳐서 해당 class label을 출력하는 것이다.
4. MLP (Classification) Head
- Transformer encoder의 output의 첫번째가 MLP head에 입력으로 들어가 final classfication 결과를 얻습니다
output vector의 0번째 값은 class token input에 대응되므로, flatten한 후 MLP Head 를 거쳐 class label을 얻는다.
'AI Tech 7기 > Computer Vision' 카테고리의 다른 글
| DreamFusion (1) | 2024.09.06 |
|---|---|
| AE(Auto Encoder), VAE(Variational Auto Encoder) (1) | 2024.09.04 |
| CNN 시각화 (0) | 2024.08.29 |
| CNN 아키텍쳐 (0) | 2024.08.29 |