
1. AE (Auto Encoder)
오토인코더는 데이터를 압축하고 복원하는 과정에서 중요한 특징들을 학습하는 것이 목적이다.
그렇기 때문에 학습한 대로 어떤 이미지를 넣으면 그대로 복원하는 것은 가능하지만, 잠재공간 벡터를 사용자가 조절해서 새로운 이미지를 생성해내는 데에는 한계가 있다. (그래서 생성형 모델이 아니다.)
encoder + latent space + decoder 의 구조로 이루어져 있고 각각의 역할은 다음과 같다.
encoder : 데이터를 입력받아 더 작은 차원으로 압축
latent space : 잠재공간
decoder : 인코더에서 만들어진 압축된 표현을 다시 원래대로 복원
일종의 self supervised training (비지도 학습)
label 데이터 없이 학습하며, 원본 데이터와 복원된 데이터 사이의 차이, reconstruction loss 를 최소화하는 방향으로 학습한다.
원본 데이터와 똑같은 데이터로 만들어내는데 어떻게 데이터의 중요한 특성을 잡을 수 있을까?
-> 차원 축소 (불필요한 정보를 제거하고, 중요한 정보를 유지함으로써 모델의 성능 개선)
(활용)
중요 특성 학습, 이미지 노이즈 제거, 데이터 복원
2. VAE (Variational Auto Encoder)
AE와 가장 큰 차이점은 AE는 latent space에서 고정된 벡터로 학습하는 반면에, VAE는 latent space에서 특정 분포를 학습하여 새로운 데이터를 생성할 수 있다. 다시 말해서, AE의 잠재공간은 단순한 벡터 공간인 반면, VAE는 잠재공간을 평균과 분산의 확률 분포로 모델링한다는 것이다.
확률 분포를 학습하기 때문에 KL 발산을 최소화 하는 방식으로 학습한다.
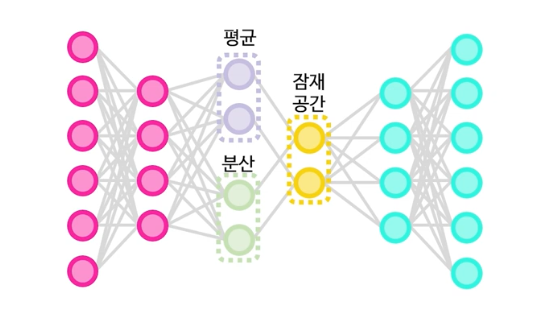
잠재공간을 정규분포를 이용해 만들기 때문에, 주어진 이미지의 숨겨진 특성을 평균과 분산을 통해 잘 이해할 수 있고, 그러한 잠재공간 분포를 잘 알고 있기 때문에, 이미지의 특정 형태를 예측하여 생성하는 것 또한 가능하다.
VAE를 활용한 Stable diffusion 모델에 이르면 이미지 생성 가능해진다.
AE는 원본 이미지를 언제든지 reconstruct 할 수 있는 Z를 만드는 것이 목적이므로 Encoder에 목적을 두는 반면, VAE는 원본 이미지가 어떻게 생성될 수 있는지에 대한 Z의 확률 분포를 학습하는 것이 목적이므로 Decoder에 목적을 둔다.
* 참고
'AI Tech 7기 > Computer Vision' 카테고리의 다른 글
| DreamFusion (1) | 2024.09.06 |
|---|---|
| CNN 시각화 (0) | 2024.08.29 |
| Vision Transformer (0) | 2024.08.29 |
| CNN 아키텍쳐 (0) | 2024.08.29 |