
1. RNN
RNN 이란 시계열 데이터를 처리하기 위한 모델로서 순환신경망을 의미한다. 이전까지는 입력에서 출력층 방향으로 진행이 되는 순방향 신경망이었다면, RNN은 결과값이 이전 노드 or 자기자신으로 돌아가는 구조이다.
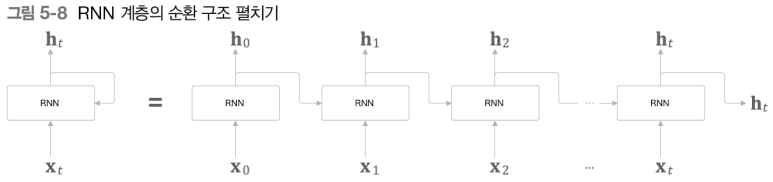
이러한 형태를 가지며, 각 계층은 그 계층으로의 입력과 이전 계층의 출력을 받는다. 즉, 현재 내 계층의 정보를 다음 시점으로 넘겨준다.
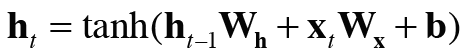
여기서 주의할 점은 t에 따라 RNN 계층이 존재하므로 각 계층에 입력되는 W 가중치 파라미터가 여러개 존재한다고 생각할 수 있지만, 실질적으로 하나다.
(장점)
즉, 시각 t에 대하여 모두 같은 가중치를 가지고 학습하고, 역전파를 통해 가중치가 업데이트 되면 모든 t에 대해서 동일하게 적용되기 때문에 가중치가 공유되는 방식이다. 그렇기 때문에 입력이 많아져도 모델의 크기가 증가하지 않는다.
(단점)
하지만 일정 시점의 값을 계산하려면 그 전의 값들을 모두 실행한 후에 진행되므로 병렬화가 어렵고, 장거리 의존성(가장 최근 정보만 기억하고, 옛날 정보는 잘 기억 못함) 을 모델링 하는데 실패했다. 또한, layer가 깊어질수록 역전파시 전달되는 기울기 값이 소실되면서 기울기 소실 문제가 발생한다.
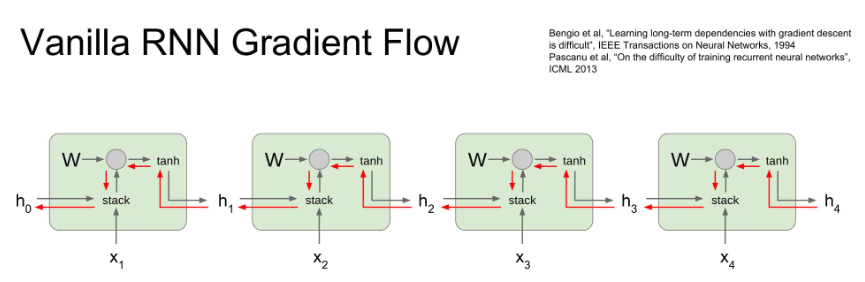
위의 사진을 보면 해당 input의 개수(cell 개수) 만큼 W.T 행렬을 계속 곱하게 된다. 이를 계속하다보면 행렬의 특이값이 1보다 크면 기울기 폭발의 문제를 가지고 1보다 작으면 기울기 소실의 문제를 야기한다. 즉, 장거리 의존성에 실패한 원인이 된다.
기울기 폭발의 문제는 그래디언트를 특정 임계값을 기준으로 clip 을 하면 된다. (임계값 넘는 기울기 값을 비례적으로 축소하여 설정)
하지만 기울기 소실의 문제를 해결할 수 없어 해결방안으로 나온 것이 LSTM 이다.
2. LSTM
위의 RNN 에서 가장 큰 문제점이 기울기 소실이었는데, 그것은 역전파 과정(FC layer)에서 행렬을 너무 많이 곱해지면서 발생했다.
이를 방지하기 위해 새로운 cell state 라는 FC 계층을 우회하는 highway를 도입했다. 이를 통해 기울기 소실 문제와 장기 의존성 문제를 해결할 수 있다.
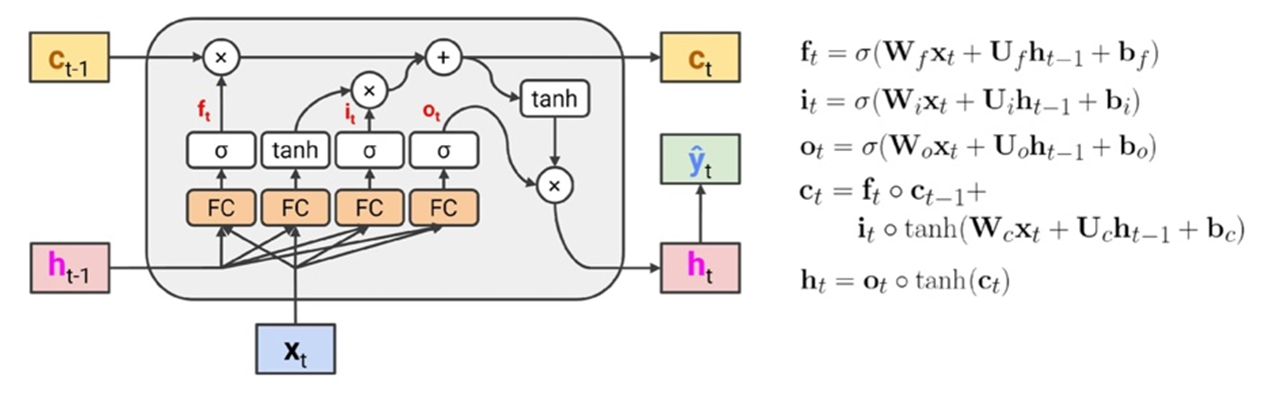
전체적인 구조는 이와 같다.
cell state를 중심으로 돌아가는 방식이며, 각 상황에서 내 정보를 cell state에 저장해서 다음 단계로 전달시키는 방식이다.
LSTM 은 3개의 gate를 가지는데,
1) forget gate : 현재 입력과 이전 cell state 로부터 어떤 정보를 버릴 것인지 정하는 게이트, sigmoid layer에 의해 결정
값이 1에 가까울수록 cell state 의 정보를 잊고 현재 데이터를 저장하고 0에 가까울수록 현재 데이터를 잊는다.
2) input gate : cell state에 현재 정보를 얼마나 저장할 것인지 정하는 게이트, sigmoid layer 에 의해 결정
이전 게이트에서 나온 값이 tanh 를 통해서 나오는데 pointwise 곱으로 얼마나 저장할지를 결정. 0에 가까울수록 cell state 에 현재 정보를 추가하지 않는다는 것을 의미하고, 1에 가까울수록 현재 정보를 많이 추가함을 의미한다.
3) output gate : cell state를 바탕으로 어떤 정보를 내보낼 것인지 정하는 게이트, sigmoid layer에 의해 결정
이를 통해, 모델이 장기 의존성을 학습하기에 더 쉬운 방법을 제공한다.
3. Seq2seq
seq2seq는 LSTM을 활용하여 기계번역에서 대표적으로 사용되는 모델이다.
(성능 문제로 인코더, 디코더를 이루는 셀은 RNN 이 아니라 LSTM이나 GRU로 구성된다. )
위에서 살펴봤던 RNN 의 큰 단점 중 하나는 1:1 관계를 가정한다는 것이다. 기계번역같은 경우는 언어별 문장의 어순이 다르기 때문에 1:1 관계를 보장할 수 없기 때문이다.
그렇기 때문에 seq2seq 모델은 인코더를 통해서 전체 문장에 대한 정보를 담고 있는 context vector를 만들고, 거기에서 디코더를 통해서 번역 결과를 추론할 수 있도록 한다.
전체적인 구조는 다음과 같다.
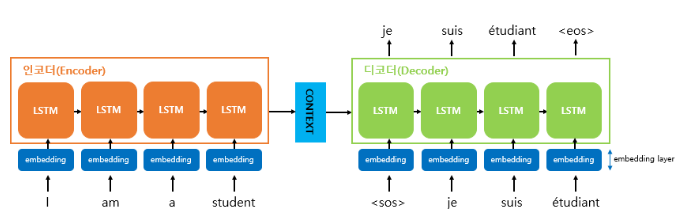
입력 sequnce 를 처리하는 부분을 인코더, 출력 sequence 를 생성하는 부분을 디코더 라고 한다.
인코더는 많은 단어를 입력으로 받아 하나의 context vector를 생성하므로 many-to-one 특성을 가지고,
디코더는 하나의 context vector를 가지고 여러 단어를 예측하므로 one-to-many 특성을 가진다.
< 인코더 >
1. 문장을 입력으로 받아 단어 단위로 쪼갠 후 (단어 토큰화) 벡터로 변환한다(워드 임베딩)
2. 이 임베딩 벡터들이 각각 인코더의 input으로 들어간다.
3. 각 셀은 이전 정보를 담고 있으므로 (LSTM의 cell state) 마지막 층의 hidden state는 이전 층의 정보를 다 담고 있다.
4. 인코더의 마지막 hidden state를 context vector 로 사용하여 디코더의 첫번째 셀로 넘겨준다.
< 디코더 >
1-1. 학습단계라면 <sos> 심볼이 들어가고 다음 input부터 이전 셀의 정답 y값이 들어간다. (teacher forcing)
1-2. 추론단계라면 <sos> 심볼이 들어가고 다음 input부터 원래대로 이전 셀에서 나온 출력 단어가 들어간다.
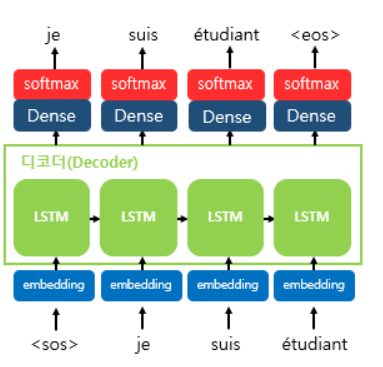
2. 인코더에서 전달받은 context vector를 첫번째 은닉상태의 값으로 사용하여 단어를 예측한다.
2-1. 각 셀에서 출력 벡터가 나오면 소프트맥스 함수를 통해 각 단어별 확률값으로 반환하고, 출력 단어 를 예측한다.
3. 이 과정을 문장의 끝을 의미하는 <eos> 심볼이 예측될 때까지 반복한다.
'AI Tech 7기 > ML LifeCycle' 카테고리의 다른 글
| 선형모델, 2층 신경망 from scratch 실습 (0) | 2024.08.20 |
|---|---|
| 신경망 모델 학습 과정 (0) | 2024.08.16 |
| 선형회귀, k-NN, 선형분류, 소프트맥스 (0) | 2024.08.16 |
| 머신러닝 기초 (0) | 2024.08.13 |
1. RNN
RNN 이란 시계열 데이터를 처리하기 위한 모델로서 순환신경망을 의미한다. 이전까지는 입력에서 출력층 방향으로 진행이 되는 순방향 신경망이었다면, RNN은 결과값이 이전 노드 or 자기자신으로 돌아가는 구조이다.
이러한 형태를 가지며, 각 계층은 그 계층으로의 입력과 이전 계층의 출력을 받는다. 즉, 현재 내 계층의 정보를 다음 시점으로 넘겨준다.
여기서 주의할 점은 t에 따라 RNN 계층이 존재하므로 각 계층에 입력되는 W 가중치 파라미터가 여러개 존재한다고 생각할 수 있지만, 실질적으로 하나다.
(장점)
즉, 시각 t에 대하여 모두 같은 가중치를 가지고 학습하고, 역전파를 통해 가중치가 업데이트 되면 모든 t에 대해서 동일하게 적용되기 때문에 가중치가 공유되는 방식이다. 그렇기 때문에 입력이 많아져도 모델의 크기가 증가하지 않는다.
(단점)
하지만 일정 시점의 값을 계산하려면 그 전의 값들을 모두 실행한 후에 진행되므로 병렬화가 어렵고, 장거리 의존성(가장 최근 정보만 기억하고, 옛날 정보는 잘 기억 못함) 을 모델링 하는데 실패했다. 또한, layer가 깊어질수록 역전파시 전달되는 기울기 값이 소실되면서 기울기 소실 문제가 발생한다.
위의 사진을 보면 해당 input의 개수(cell 개수) 만큼 W.T 행렬을 계속 곱하게 된다. 이를 계속하다보면 행렬의 특이값이 1보다 크면 기울기 폭발의 문제를 가지고 1보다 작으면 기울기 소실의 문제를 야기한다. 즉, 장거리 의존성에 실패한 원인이 된다.
기울기 폭발의 문제는 그래디언트를 특정 임계값을 기준으로 clip 을 하면 된다. (임계값 넘는 기울기 값을 비례적으로 축소하여 설정)
하지만 기울기 소실의 문제를 해결할 수 없어 해결방안으로 나온 것이 LSTM 이다.
2. LSTM
위의 RNN 에서 가장 큰 문제점이 기울기 소실이었는데, 그것은 역전파 과정(FC layer)에서 행렬을 너무 많이 곱해지면서 발생했다.
이를 방지하기 위해 새로운 cell state 라는 FC 계층을 우회하는 highway를 도입했다. 이를 통해 기울기 소실 문제와 장기 의존성 문제를 해결할 수 있다.
전체적인 구조는 이와 같다.
cell state를 중심으로 돌아가는 방식이며, 각 상황에서 내 정보를 cell state에 저장해서 다음 단계로 전달시키는 방식이다.
LSTM 은 3개의 gate를 가지는데,
1) forget gate : 현재 입력과 이전 cell state 로부터 어떤 정보를 버릴 것인지 정하는 게이트, sigmoid layer에 의해 결정
값이 1에 가까울수록 cell state 의 정보를 잊고 현재 데이터를 저장하고 0에 가까울수록 현재 데이터를 잊는다.
2) input gate : cell state에 현재 정보를 얼마나 저장할 것인지 정하는 게이트, sigmoid layer 에 의해 결정
이전 게이트에서 나온 값이 tanh 를 통해서 나오는데 pointwise 곱으로 얼마나 저장할지를 결정. 0에 가까울수록 cell state 에 현재 정보를 추가하지 않는다는 것을 의미하고, 1에 가까울수록 현재 정보를 많이 추가함을 의미한다.
3) output gate : cell state를 바탕으로 어떤 정보를 내보낼 것인지 정하는 게이트, sigmoid layer에 의해 결정
이를 통해, 모델이 장기 의존성을 학습하기에 더 쉬운 방법을 제공한다.
3. Seq2seq
seq2seq는 LSTM을 활용하여 기계번역에서 대표적으로 사용되는 모델이다.
(성능 문제로 인코더, 디코더를 이루는 셀은 RNN 이 아니라 LSTM이나 GRU로 구성된다. )
위에서 살펴봤던 RNN 의 큰 단점 중 하나는 1:1 관계를 가정한다는 것이다. 기계번역같은 경우는 언어별 문장의 어순이 다르기 때문에 1:1 관계를 보장할 수 없기 때문이다.
그렇기 때문에 seq2seq 모델은 인코더를 통해서 전체 문장에 대한 정보를 담고 있는 context vector를 만들고, 거기에서 디코더를 통해서 번역 결과를 추론할 수 있도록 한다.
전체적인 구조는 다음과 같다.
입력 sequnce 를 처리하는 부분을 인코더, 출력 sequence 를 생성하는 부분을 디코더 라고 한다.
인코더는 많은 단어를 입력으로 받아 하나의 context vector를 생성하므로 many-to-one 특성을 가지고,
디코더는 하나의 context vector를 가지고 여러 단어를 예측하므로 one-to-many 특성을 가진다.
< 인코더 >
1. 문장을 입력으로 받아 단어 단위로 쪼갠 후 (단어 토큰화) 벡터로 변환한다(워드 임베딩)
2. 이 임베딩 벡터들이 각각 인코더의 input으로 들어간다.
3. 각 셀은 이전 정보를 담고 있으므로 (LSTM의 cell state) 마지막 층의 hidden state는 이전 층의 정보를 다 담고 있다.
4. 인코더의 마지막 hidden state를 context vector 로 사용하여 디코더의 첫번째 셀로 넘겨준다.
< 디코더 >
1-1. 학습단계라면 <sos> 심볼이 들어가고 다음 input부터 이전 셀의 정답 y값이 들어간다. (teacher forcing)
1-2. 추론단계라면 <sos> 심볼이 들어가고 다음 input부터 원래대로 이전 셀에서 나온 출력 단어가 들어간다.
2. 인코더에서 전달받은 context vector를 첫번째 은닉상태의 값으로 사용하여 단어를 예측한다.
2-1. 각 셀에서 출력 벡터가 나오면 소프트맥스 함수를 통해 각 단어별 확률값으로 반환하고, 출력 단어 를 예측한다.
3. 이 과정을 문장의 끝을 의미하는 <eos> 심볼이 예측될 때까지 반복한다.
'AI Tech 7기 > ML LifeCycle' 카테고리의 다른 글
| 선형모델, 2층 신경망 from scratch 실습 (0) | 2024.08.20 |
|---|---|
| 신경망 모델 학습 과정 (0) | 2024.08.16 |
| 선형회귀, k-NN, 선형분류, 소프트맥스 (0) | 2024.08.16 |
| 머신러닝 기초 (0) | 2024.08.13 |