
목차
1. Activation fucntion
2. Initialize weights
3. Loss function
4. Backward propagation
5. Optimization
5-1. Learning rate scheduler
신경망 모델은 입력층, 은닉층, 출력층으로 구성되어 있으며 선형 모델과 달리 비선형 활성화함수들을 통해 비선형 관계를 학습할 수 있다. 따라서 더 복잡한 패턴을 학습할 수 있으며 모델의 표현력이 풍부해진다.
신경망 모델의 학습 과정과 추론 과정을 순서대로 살펴본다면,
< 학습 과정 >
1. forward propagation (순전파) : 입력 데이터가 모델을 통과하여 최종적으로 예측된 결과를 생성한다.
2. Loss function (손실 계산) : 예측값과 실제값 사이의 차이를 손실함수로 계산한다.
3. backward propagation (역전파) : 손실을 최소화하기 위해 가중치의 기울기를 계산하고 순전파의 반대방향으로 흘려보낸다.
4. optimization (최적화) : 최적화 알고리즘을 사용하여 계산된 기울기에 따라 가중치를 업데이트한다.
위의 과정을 반복하여 손실이 최소화할 수 있도록 한다.
< 평가 과정 >
5. validation set으로 나눴다면 모델의 성능을 평가하고, 하이퍼파라미터를 조정한다.
< 추론 과정 >
6. forward propagation (순전파) : 새로운 데이터로 (test data) 모델에 입력하여 예측 결과를 생성한다.
각 단계에서 어떻게 행해지는지 살펴보겠다.
1. Activation function (활성화함수) - (1. 순전파)
신경망 모델은 비선형 활성화함수를 거쳐 다음 층으로 전달된다. 층이 깊어질수록 학습이 더딘 이유는 활성화함수에 있을 수 있다. 시그모이드 함수를 사용하게 되면 기울기가 0~1 이며 층을 더해갈수록 더 0에 가까운 값이 되기 때문이다.
그래서 주로 출력층 활성화함수로 시그모이드 함수를 사용한다. 다른 층에서는 ReLU 를 많이 사용한다.
< sigmoid 함수 >
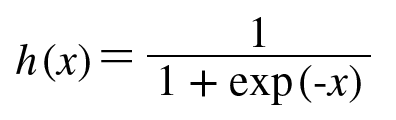
가장 많이 사용되는 함수이며, 0~1 사이의 값을 출력한다.
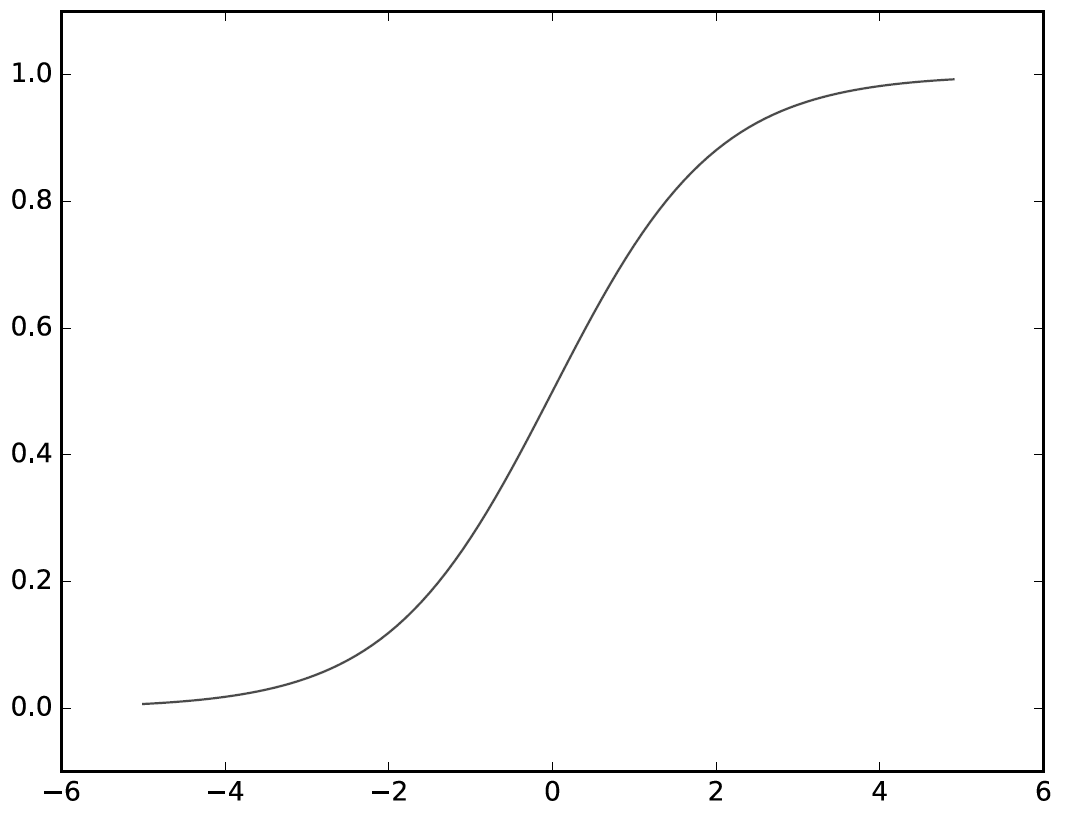
1. 기울기 소실
하지만, input이 작거나 크게 되면 기울기가 0에 가까워진다.
역전파시 전달되는 기울기가 0에 가까운 수가 되어버리므로 가중치 업데이트가 잘 안된다.
2. not zero centered output
출력값이 0~1 사이의 값이므로 역전파시 전달되는 기울기 값이 모두 양수거나 모두 음수다.
그렇기 때문에 특정 방향으로만 업데이트가 된다.
< tanh 함수 >
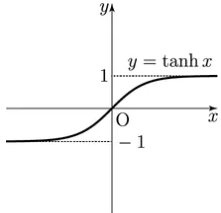
sigmoid 함수에서 출력값이 -1 ~ 1 로 확장된 형태다.
zero centered output 이지만 마찬가지로 input이 작거나 크게 되면 기울기가 0에 가까워지는 기울기 소실 문제가 남아있다.
< ReLU, Leaky ReLU, ELU 함수 >
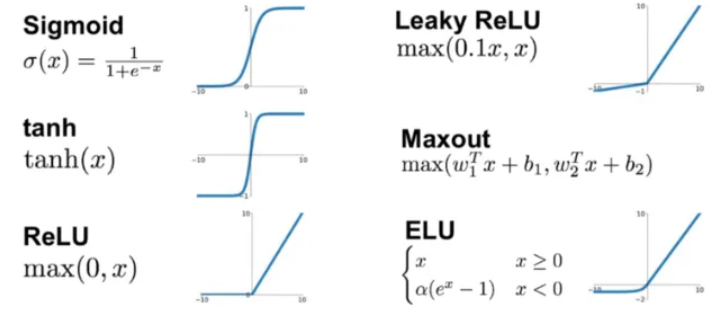
양수인 영역에서 기울기가 0이 되지 않는다.
ReLU 함수는 음수인 영역에서 기울기가 0이 되면서 기울기 소실 문제가 발생하지만, Leaky ReLU 나 ELU 함수는 모든 영역에서 기울기가 존재하며 견고성을 가진다.
2. Initialize weights (가중치 초기화)
신경망 모델은 입력층, 은닉층, 출력층으로 구성되어 있으며 이전 층에서 다음 층으로 넘어갈 때 가중치를 곱하거나 활성화함수를 거쳐 전달된다. 그렇다면, 가중치는 어떤 값으로 초기화 되는지 알아보자.
가중치는 0에 가까운 수들로 랜덤하게 초기화 해야한다.
- 0에 가까운 수가 아니라면 ? 시그모이드 함수 같은 경우 입력값이 크거나 작으면 기울기가 0에 매우 가까워진다. 그렇게 되면 역전파시 기울기 소실, 기울기 폭주의 문제를 일으킬 수 있다.
- 랜덤하게 하지 않는다면 ? 모두 같은 값으로 초기화하게 되면 역전파시 모든 가중치의 값이 똑같이 갱신된다. 그러므로 대칭적인 구조를 무너뜨려야한다.
가장 많이 사용되는 방법은 표준정규분포 (randn) 로 하거나 균등분포 (rand) 로 초기화 되는 경우가 많았다.
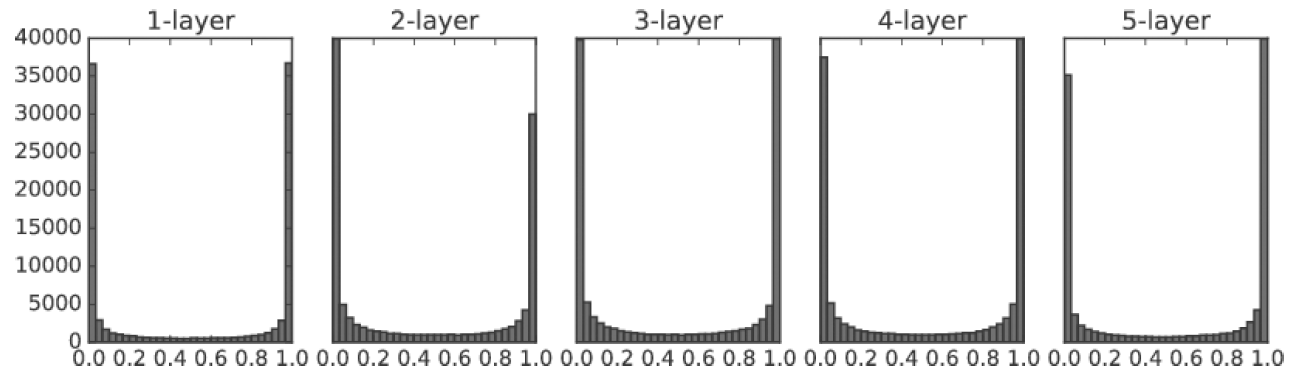
표준편차가 1인 정규분포로 초기화
활성화함수로는 시그모이드 함수를 사용
-> 층이 깊어질수록 0과 1에 값이 많이 분포
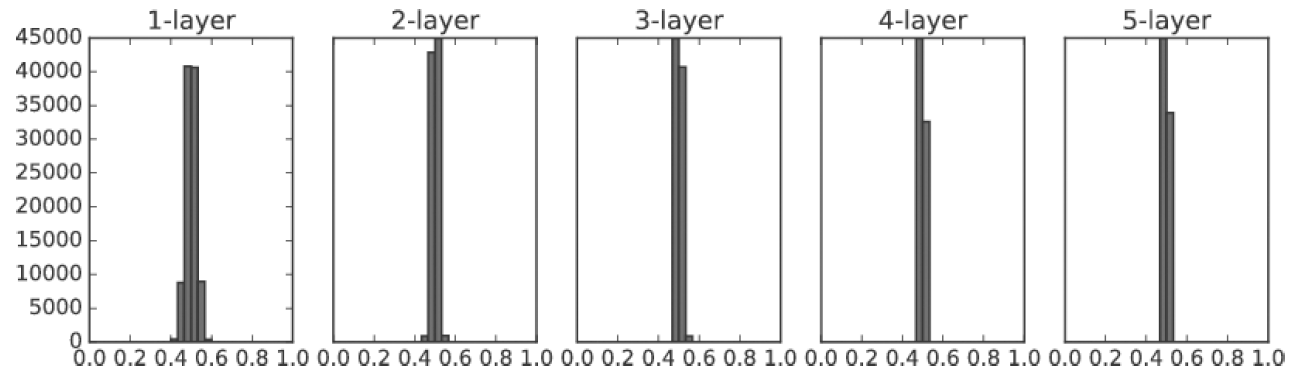
표준편차가 0.01인 정규분포로 초기화
(값이 주로 -0.05 ~ 0.05)
활성화함수로는 시그모이드 함수를 사용
-> 입력값이 계속 0 주변에 머물면서 층이 깊어질수록 0.5에 값이 많이 분포
이렇기 때문에 권장되는 Xavier 초기값에 대해서 알아보자.
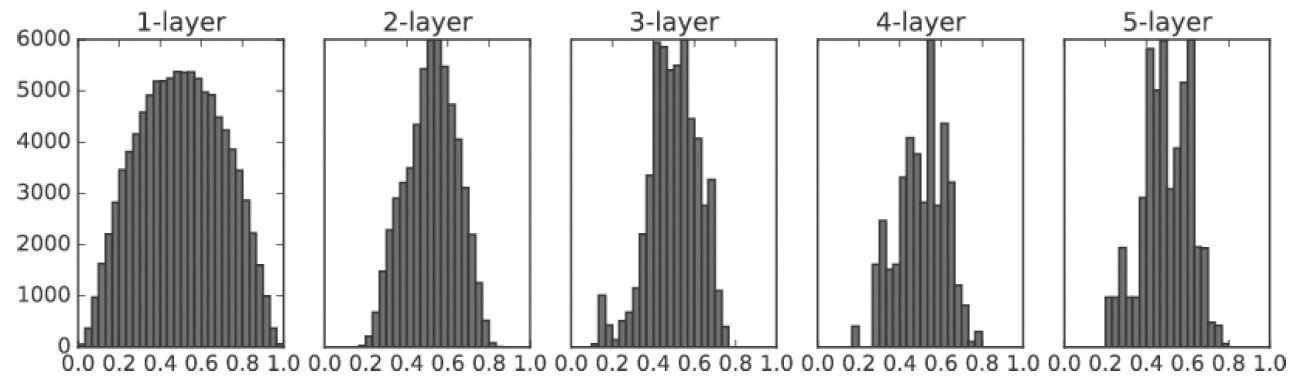
표준편차가 1/sqrt(n) (n:앞 계층의 노드 개수) 인 정규분포로 초기화하면 위의 경우와는 달리 확실히 넓게 분포됨을 볼 수 있다.
여기서는 sigmoid 를 사용해서 모양이 일그러졌지만, tanh 함수를 사용하면 종 모양으로 분포된다.
활성화함수가 ReLU 일 때는 He 초깃값이 더 권장된다.
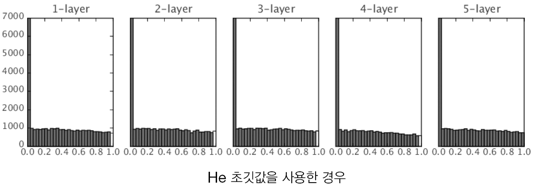
표준편차가 sqrt(2/n) (n:앞 계층의 노드 개수) 인 정규분포로 초기화하면 ReLU 함수에서 더 균일한 분포를 가진다.
그래서, 활성화 함수가 S자 모양 곡선 (tanh, sigmoid) 의 경우에는 Xavier 초기값을 사용하고, ReLU의 경우에는 He 초기값을 사용하면 좋다.
3. Loss function (손실 함수) - (2. 손실계산)
손실함수는 모델을 통해 계산된 예측값과 실제값의 차이를 계산해주는 함수다. 대표적인 손실함수로 MSE와 교차엔트로피가 있다. MSE 는 이전장에서 살펴봤으므로 교차엔트로피와 KL 발산에 대해서 보겠다.
< 교차 엔트로피 >
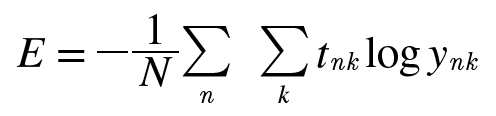
식은 다음과 같다. t 는 정답 레이블이고 y 는 신경망의 출력이다.
t는 정답 레이블에만 1 값이 있는 원핫인코딩 형식이므로 실질적으로 정답 일 때의 예측값의 자연로그를 계산하는 식이 된다. (그렇기 때문에 출력층의 활성화함수는 소프트맥스 함수를 사용함 -> 신경망의 출력 또한 0~1값이 되도록)
즉, 정답일 때의 예측값이 1에 가까우면 교차엔트로피 값은 0에 가깝고, 예측값이 0에 가까우면 교차엔트로피 값은 커진다.
< KL 발산 >
두 확률분포의 차이를 계산하는데 사용하는 함수로, 이상적인 분포(정답 y) 에 대해 그 분포를 근사하는 다른 분포(예측값 y_hat) 를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산한다.
손실함수를 설정하는 이유는 최적의 가중치를 찾기 위해서다. 역전파때 손실함수를 가중치에 대해서 미분한다는 것은 '해당 가중치의 값을 아주 조금 변화시켰을 때 손실함수가 어떻게 변하냐' 를 의미한다. 이렇게 된다면 손실함수를 줄이는 방향으로 가중치의 값을 업데이트 시킬 수 있는 것이다.
4. Backward propagation (역전파 계산) - (3. 역전파)
위에서 계산한 손실 함수 값을 해당 매개변수(가중치, 편향) 으로 미분하여 그 변화량을 확인하고 매개변수를 업데이트 하기 위해 '미분' 하는 방법에 대해서 알아보겠다.
역전파 계산은 연쇄법칙과 편미분에 기반해있다.
간단하게 설명한다면, downstream gradient 는 local gradient 와 upstream gradient 의 곱으로 나타낼 수 있다.
활성화 함수 계층을 역전파로 구현해보자.
< ReLU 함수 >
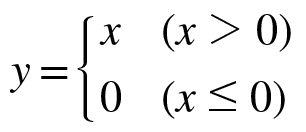
ReLU 함수와 x에 대한 y의 미분 식은 다음과 같다.
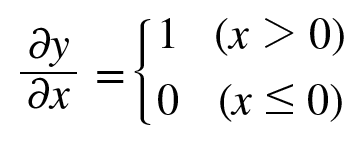
여기서 보면 순전파때 입력값인 x가 0보다 크면 역전파는 상류의 값을 그대로 흘려보내고
x 가 0보다 작으면 역전파는 하류로 흘려보내지 않는다.
< sigmoid 함수 >
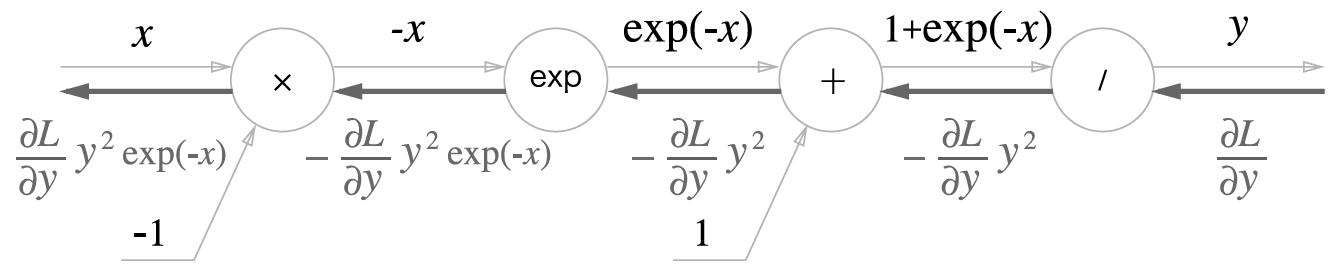
시그모이드 함수의 역전파는 좌측과같이 표현할 수 있으며, 최종 값을 다시 표현하면 맨 아래 사진과 같다.
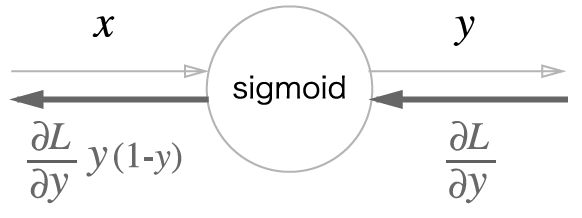
위의 계산은 해당 계산 그래프의 노드에 적힌 계산을 미분한 값을 곱해주며 전달해간다.
기본적으로 회귀분석을 할 때는 출력층의 활성화함수와 손실함수의 조합이 (항등함수, SSE) 가 많이 쓰이고,
분류분석을 할 때는 (소프트맥스, 교차엔트로피) 의 조합이 많이 쓰인다.
그런데, 역전파 계산할 시 두 층을 통해 전달 되는 값은 똑같이 y-t 라는 공통점이 있다. 이를 계산해보면 다음과 같다.
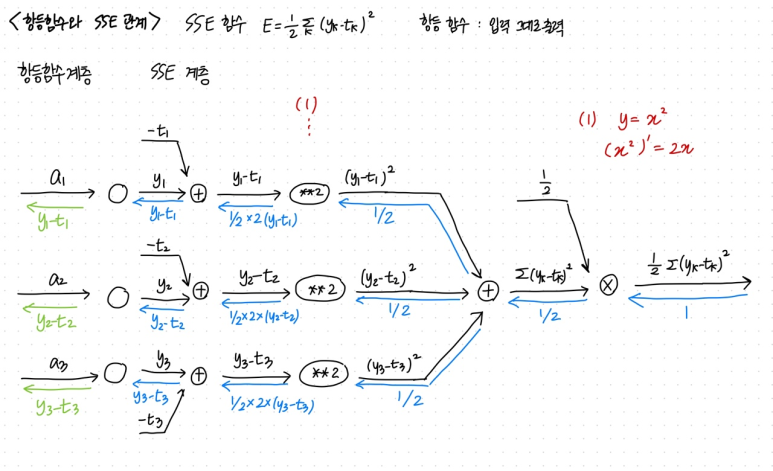
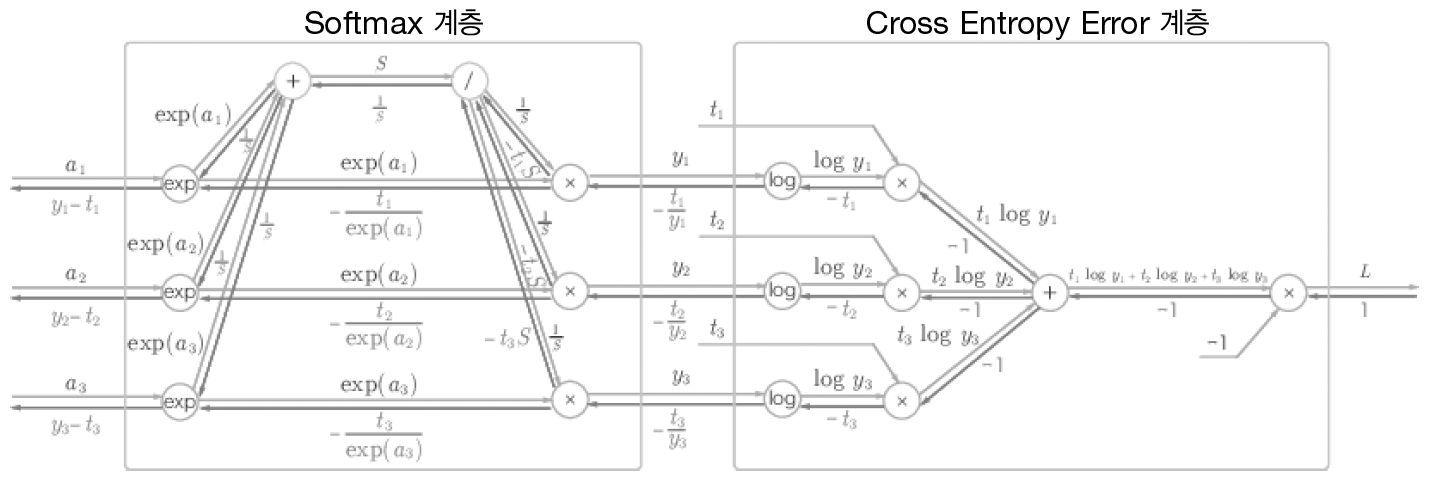
5. Optimization (최적화) - (4. 최적화)
지금까지 손실값도 구했고, 손실값을 매개변수로 미분해서 역전파를 통해 흘려보내는 방법도 공부했다.
그러면 이제 그 미분한 값을 이용해서 '매개변수를 어떻게 업데이트 시킬지'에 대해 알아보자.
그 과정을 최적화라고 하는데, some criterion 에 따라서 best element (최적의 매개변수) 를 찾는 과정이다.
< 경사하강법 (배치경사하강법) , GD>
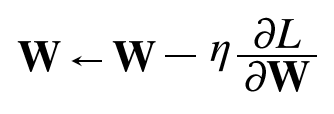
손실함수를 각 매개변수로 미분하고 그것을 줄이는 방향으로 가중치를 업데이트 한다.
한 번의 학습으로 얼마나 줄일지는 앞에 곱해진 학습률을 통해 정한다.
하지만 이 방법의 최대 단점이 있다. 모든 데이터에서 계산되므로 시간이 오래 걸린다.
즉, 한 지점에서 모든 방향의 기울기를 계산하고 가장 가파른 방향 (가장 최소가 되는 방향)으로 업데이트 하는 방식이다.
< 확률적경사하강법, SGD >
모든 데이터에 대해서 계산 하는 것이 아니라, 무작위로 샘플링된 1개의 데이터에 대해서만 가중치를 업데이트 하는 방식이다. 즉, 각 데이터에 대해 개별적으로 가중치를 업데이트 한다.
< 미니배치경사하강법 >
데이터셋을 여러개의 작은 배치로 나누어 배치 단위로 가중치를 업데이트 한다.
미니배치 크기가 작을 경우에는 전체 데이터셋을 대표하는 성질이 사라져 noise 가 발생할 수 있다.
데이터가 10개가 있고 (미니배치의 경우 한 배치당 2개) 3가지 방법을 생각해본다면,
GD는 데이터 10개를 통해서 기울기 계산 후 각 epoch 마다 1번의 파라미터 업데이트,
SGD는 데이터 1개마다 기울기 계산 후 각 epoch 마다 10번의 파라미터 업데이트,
mini batch GD 는 데이터 2개마다 기울기 계산 후 각 epoch 마다 5번의 파라미터 업데이트
과정이 이루어진다.
< Adam >
Adam 은 가장 무난하게 성능이 잘 나오는 최적화 기법이다. RMSProp과 Adagrad 의 장점이 합쳐진 기법으로 각 파라미터의 기울기에 대한 평균과, 제곱 평균을 하이퍼파라미터를 정해 가중치를 업데이트 한다.
5-1. Learning rate scheduler (학습률 스케쥴러)
다음은 최적화 과정에서 하이퍼파라미터로 정하는 학습률을 어떻게 설정할 것인가에 대해 살펴보겠다.
학습률이 크면 모델이 빠르게 학습하지만, 최소값을 중심으로 진동하거나 뛰어 넘을 수도 있다. 반면, 학습률이 작으면 가중치 업데이트가 작아서 최소값을 향해 천천히 움직이게 되므로 시간이 오래 걸리거나 local minimum에 빠질 확률이 높다.
이렇기 때문에 학습 과정에서 학습률을 동적으로 조정하는 학습률 스케쥴러가 도입됐다. 주로 처음에는 큰 학습률을 사용하여 학습한 후, 최적의 해에 접근하기 위해 학습률을 낮추는 것이 일반적이다.
< Step Decay >
고정된 학습 포인트에서 (특정 epoch마다) 학습률을 일정한 비율로 감소시켜 주는 방법이다.
'AI Tech 7기 > ML LifeCycle' 카테고리의 다른 글
| 선형모델, 2층 신경망 from scratch 실습 (0) | 2024.08.20 |
|---|---|
| RNN, LSTM, seq2seq 모델 (1) | 2024.08.16 |
| 선형회귀, k-NN, 선형분류, 소프트맥스 (0) | 2024.08.16 |
| 머신러닝 기초 (0) | 2024.08.13 |
목차
1. Activation fucntion
2. Initialize weights
3. Loss function
4. Backward propagation
5. Optimization
5-1. Learning rate scheduler
신경망 모델은 입력층, 은닉층, 출력층으로 구성되어 있으며 선형 모델과 달리 비선형 활성화함수들을 통해 비선형 관계를 학습할 수 있다. 따라서 더 복잡한 패턴을 학습할 수 있으며 모델의 표현력이 풍부해진다.
신경망 모델의 학습 과정과 추론 과정을 순서대로 살펴본다면,
< 학습 과정 >
1. forward propagation (순전파) : 입력 데이터가 모델을 통과하여 최종적으로 예측된 결과를 생성한다.
2. Loss function (손실 계산) : 예측값과 실제값 사이의 차이를 손실함수로 계산한다.
3. backward propagation (역전파) : 손실을 최소화하기 위해 가중치의 기울기를 계산하고 순전파의 반대방향으로 흘려보낸다.
4. optimization (최적화) : 최적화 알고리즘을 사용하여 계산된 기울기에 따라 가중치를 업데이트한다.
위의 과정을 반복하여 손실이 최소화할 수 있도록 한다.
< 평가 과정 >
5. validation set으로 나눴다면 모델의 성능을 평가하고, 하이퍼파라미터를 조정한다.
< 추론 과정 >
6. forward propagation (순전파) : 새로운 데이터로 (test data) 모델에 입력하여 예측 결과를 생성한다.
각 단계에서 어떻게 행해지는지 살펴보겠다.
1. Activation function (활성화함수) - (1. 순전파)
신경망 모델은 비선형 활성화함수를 거쳐 다음 층으로 전달된다. 층이 깊어질수록 학습이 더딘 이유는 활성화함수에 있을 수 있다. 시그모이드 함수를 사용하게 되면 기울기가 0~1 이며 층을 더해갈수록 더 0에 가까운 값이 되기 때문이다.
그래서 주로 출력층 활성화함수로 시그모이드 함수를 사용한다. 다른 층에서는 ReLU 를 많이 사용한다.
< sigmoid 함수 >
가장 많이 사용되는 함수이며, 0~1 사이의 값을 출력한다.
1. 기울기 소실
하지만, input이 작거나 크게 되면 기울기가 0에 가까워진다.
역전파시 전달되는 기울기가 0에 가까운 수가 되어버리므로 가중치 업데이트가 잘 안된다.
2. not zero centered output
출력값이 0~1 사이의 값이므로 역전파시 전달되는 기울기 값이 모두 양수거나 모두 음수다.
그렇기 때문에 특정 방향으로만 업데이트가 된다.
< tanh 함수 >
sigmoid 함수에서 출력값이 -1 ~ 1 로 확장된 형태다.
zero centered output 이지만 마찬가지로 input이 작거나 크게 되면 기울기가 0에 가까워지는 기울기 소실 문제가 남아있다.
< ReLU, Leaky ReLU, ELU 함수 >
양수인 영역에서 기울기가 0이 되지 않는다.
ReLU 함수는 음수인 영역에서 기울기가 0이 되면서 기울기 소실 문제가 발생하지만, Leaky ReLU 나 ELU 함수는 모든 영역에서 기울기가 존재하며 견고성을 가진다.
2. Initialize weights (가중치 초기화)
신경망 모델은 입력층, 은닉층, 출력층으로 구성되어 있으며 이전 층에서 다음 층으로 넘어갈 때 가중치를 곱하거나 활성화함수를 거쳐 전달된다. 그렇다면, 가중치는 어떤 값으로 초기화 되는지 알아보자.
가중치는 0에 가까운 수들로 랜덤하게 초기화 해야한다.
- 0에 가까운 수가 아니라면 ? 시그모이드 함수 같은 경우 입력값이 크거나 작으면 기울기가 0에 매우 가까워진다. 그렇게 되면 역전파시 기울기 소실, 기울기 폭주의 문제를 일으킬 수 있다.
- 랜덤하게 하지 않는다면 ? 모두 같은 값으로 초기화하게 되면 역전파시 모든 가중치의 값이 똑같이 갱신된다. 그러므로 대칭적인 구조를 무너뜨려야한다.
가장 많이 사용되는 방법은 표준정규분포 (randn) 로 하거나 균등분포 (rand) 로 초기화 되는 경우가 많았다.
표준편차가 1인 정규분포로 초기화
활성화함수로는 시그모이드 함수를 사용
-> 층이 깊어질수록 0과 1에 값이 많이 분포
표준편차가 0.01인 정규분포로 초기화
(값이 주로 -0.05 ~ 0.05)
활성화함수로는 시그모이드 함수를 사용
-> 입력값이 계속 0 주변에 머물면서 층이 깊어질수록 0.5에 값이 많이 분포
이렇기 때문에 권장되는 Xavier 초기값에 대해서 알아보자.
표준편차가 1/sqrt(n) (n:앞 계층의 노드 개수) 인 정규분포로 초기화하면 위의 경우와는 달리 확실히 넓게 분포됨을 볼 수 있다.
여기서는 sigmoid 를 사용해서 모양이 일그러졌지만, tanh 함수를 사용하면 종 모양으로 분포된다.
활성화함수가 ReLU 일 때는 He 초깃값이 더 권장된다.
표준편차가 sqrt(2/n) (n:앞 계층의 노드 개수) 인 정규분포로 초기화하면 ReLU 함수에서 더 균일한 분포를 가진다.
그래서, 활성화 함수가 S자 모양 곡선 (tanh, sigmoid) 의 경우에는 Xavier 초기값을 사용하고, ReLU의 경우에는 He 초기값을 사용하면 좋다.
3. Loss function (손실 함수) - (2. 손실계산)
손실함수는 모델을 통해 계산된 예측값과 실제값의 차이를 계산해주는 함수다. 대표적인 손실함수로 MSE와 교차엔트로피가 있다. MSE 는 이전장에서 살펴봤으므로 교차엔트로피와 KL 발산에 대해서 보겠다.
< 교차 엔트로피 >
식은 다음과 같다. t 는 정답 레이블이고 y 는 신경망의 출력이다.
t는 정답 레이블에만 1 값이 있는 원핫인코딩 형식이므로 실질적으로 정답 일 때의 예측값의 자연로그를 계산하는 식이 된다. (그렇기 때문에 출력층의 활성화함수는 소프트맥스 함수를 사용함 -> 신경망의 출력 또한 0~1값이 되도록)
즉, 정답일 때의 예측값이 1에 가까우면 교차엔트로피 값은 0에 가깝고, 예측값이 0에 가까우면 교차엔트로피 값은 커진다.
< KL 발산 >
두 확률분포의 차이를 계산하는데 사용하는 함수로, 이상적인 분포(정답 y) 에 대해 그 분포를 근사하는 다른 분포(예측값 y_hat) 를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산한다.
손실함수를 설정하는 이유는 최적의 가중치를 찾기 위해서다. 역전파때 손실함수를 가중치에 대해서 미분한다는 것은 '해당 가중치의 값을 아주 조금 변화시켰을 때 손실함수가 어떻게 변하냐' 를 의미한다. 이렇게 된다면 손실함수를 줄이는 방향으로 가중치의 값을 업데이트 시킬 수 있는 것이다.
4. Backward propagation (역전파 계산) - (3. 역전파)
위에서 계산한 손실 함수 값을 해당 매개변수(가중치, 편향) 으로 미분하여 그 변화량을 확인하고 매개변수를 업데이트 하기 위해 '미분' 하는 방법에 대해서 알아보겠다.
역전파 계산은 연쇄법칙과 편미분에 기반해있다.
간단하게 설명한다면, downstream gradient 는 local gradient 와 upstream gradient 의 곱으로 나타낼 수 있다.
활성화 함수 계층을 역전파로 구현해보자.
< ReLU 함수 >
ReLU 함수와 x에 대한 y의 미분 식은 다음과 같다.
여기서 보면 순전파때 입력값인 x가 0보다 크면 역전파는 상류의 값을 그대로 흘려보내고
x 가 0보다 작으면 역전파는 하류로 흘려보내지 않는다.
< sigmoid 함수 >
시그모이드 함수의 역전파는 좌측과같이 표현할 수 있으며, 최종 값을 다시 표현하면 맨 아래 사진과 같다.
위의 계산은 해당 계산 그래프의 노드에 적힌 계산을 미분한 값을 곱해주며 전달해간다.
기본적으로 회귀분석을 할 때는 출력층의 활성화함수와 손실함수의 조합이 (항등함수, SSE) 가 많이 쓰이고,
분류분석을 할 때는 (소프트맥스, 교차엔트로피) 의 조합이 많이 쓰인다.
그런데, 역전파 계산할 시 두 층을 통해 전달 되는 값은 똑같이 y-t 라는 공통점이 있다. 이를 계산해보면 다음과 같다.
5. Optimization (최적화) - (4. 최적화)
지금까지 손실값도 구했고, 손실값을 매개변수로 미분해서 역전파를 통해 흘려보내는 방법도 공부했다.
그러면 이제 그 미분한 값을 이용해서 '매개변수를 어떻게 업데이트 시킬지'에 대해 알아보자.
그 과정을 최적화라고 하는데, some criterion 에 따라서 best element (최적의 매개변수) 를 찾는 과정이다.
< 경사하강법 (배치경사하강법) , GD>
손실함수를 각 매개변수로 미분하고 그것을 줄이는 방향으로 가중치를 업데이트 한다.
한 번의 학습으로 얼마나 줄일지는 앞에 곱해진 학습률을 통해 정한다.
하지만 이 방법의 최대 단점이 있다. 모든 데이터에서 계산되므로 시간이 오래 걸린다.
즉, 한 지점에서 모든 방향의 기울기를 계산하고 가장 가파른 방향 (가장 최소가 되는 방향)으로 업데이트 하는 방식이다.
< 확률적경사하강법, SGD >
모든 데이터에 대해서 계산 하는 것이 아니라, 무작위로 샘플링된 1개의 데이터에 대해서만 가중치를 업데이트 하는 방식이다. 즉, 각 데이터에 대해 개별적으로 가중치를 업데이트 한다.
< 미니배치경사하강법 >
데이터셋을 여러개의 작은 배치로 나누어 배치 단위로 가중치를 업데이트 한다.
미니배치 크기가 작을 경우에는 전체 데이터셋을 대표하는 성질이 사라져 noise 가 발생할 수 있다.
데이터가 10개가 있고 (미니배치의 경우 한 배치당 2개) 3가지 방법을 생각해본다면,
GD는 데이터 10개를 통해서 기울기 계산 후 각 epoch 마다 1번의 파라미터 업데이트,
SGD는 데이터 1개마다 기울기 계산 후 각 epoch 마다 10번의 파라미터 업데이트,
mini batch GD 는 데이터 2개마다 기울기 계산 후 각 epoch 마다 5번의 파라미터 업데이트
과정이 이루어진다.
< Adam >
Adam 은 가장 무난하게 성능이 잘 나오는 최적화 기법이다. RMSProp과 Adagrad 의 장점이 합쳐진 기법으로 각 파라미터의 기울기에 대한 평균과, 제곱 평균을 하이퍼파라미터를 정해 가중치를 업데이트 한다.
5-1. Learning rate scheduler (학습률 스케쥴러)
다음은 최적화 과정에서 하이퍼파라미터로 정하는 학습률을 어떻게 설정할 것인가에 대해 살펴보겠다.
학습률이 크면 모델이 빠르게 학습하지만, 최소값을 중심으로 진동하거나 뛰어 넘을 수도 있다. 반면, 학습률이 작으면 가중치 업데이트가 작아서 최소값을 향해 천천히 움직이게 되므로 시간이 오래 걸리거나 local minimum에 빠질 확률이 높다.
이렇기 때문에 학습 과정에서 학습률을 동적으로 조정하는 학습률 스케쥴러가 도입됐다. 주로 처음에는 큰 학습률을 사용하여 학습한 후, 최적의 해에 접근하기 위해 학습률을 낮추는 것이 일반적이다.
< Step Decay >
고정된 학습 포인트에서 (특정 epoch마다) 학습률을 일정한 비율로 감소시켜 주는 방법이다.
'AI Tech 7기 > ML LifeCycle' 카테고리의 다른 글
| 선형모델, 2층 신경망 from scratch 실습 (0) | 2024.08.20 |
|---|---|
| RNN, LSTM, seq2seq 모델 (1) | 2024.08.16 |
| 선형회귀, k-NN, 선형분류, 소프트맥스 (0) | 2024.08.16 |
| 머신러닝 기초 (0) | 2024.08.13 |